ich bin aktuell dabei, die Leistung verschiedener Speicher-Konfigurationen(HDD,SSD) im Rahmen von Virtualisierung zu testen. Als Virtualisierungsplattform habe ich mir Proxmox VE mit KVM ausgesucht. Die Anwendung ist hierbei hauptsächlich das Webumfeld, also Webserver, MySQL- und Postgres-Datenbanken und serververarbeitete Programmiersprachen.(Java, PHP, Python, ...). Das ganze möchte ich von der Geschwindigkeit her testen.
Vielleicht kann man daraus auch einen Pro-Linux-Artikel machen, wenn die Arbeit tatsächlich einen Nutzen darstellen sollte und brauchbare Ergebnisse liefert.
Abgrenzung
Wenn hochperformante Datenbanken benötigt werden, dann kommen hier geplant dedizierte Server zum Einsatz, die speziell darauf ausgelegt sind. Nichts desto trotz werden auf der Umgebung einige Datenbanken betrieben.
Was natürlich interessant ist, in dem Zusammenhang, ist Ceph. Da man dafür aber mindestens(!) mal eine 10 GBit Vernetzung braucht und am besten durchgängig auch SSDs, ist das eher eine hochpreisige Angelegenheit. Wenn man das Budget dafür hat, dann wäre das mit Sicherheit meine 1. Wahl, auch weil man dann gleich einen redundanten, netzwerkfähigen Speicher hat. Ich habe auch einen Proxmox-Hyperconverged Cluster in meiner Verwaltung mit integriertem Ceph. Der lässt sich auch wirklich gut verwalten und bringt auch die Leistung, die man sich so erwartet - natürlich zum entsprechenden Preis. Aufgrund des Preises wird hier Ceph nicht berücksichtigt.
Falls Sich einer denken mag: SSDs sind doch gar nicht so teuer: Das gilt vielleicht für einfache Consumer-Modelle(z. B. 500 GB m.2 SSD für ~50 EUR. Gesamte Schreibkapazität während der Produktlebenszeit z. B. 300 TB). Eine Server-SSD, die auch wirklich wesentlich länger betrieben werden kann ist deutlich teuerer(z. B. Intel Optane DC4800X PCIe mit 375 GB für ~1100 EUR. Gesamte Schreibkapazität während der Produktlebenszeit: 20.5 PB).
Kriterien der Speicherkonfiguration
Bzgl. der Speicherkonfiguration möchte ich folgende Bereiche testen:
- verschiedene Dateisysteme
- LVM
- Transparente Kompression(zfs/btrfs)
- Thin Provisioning(zfs/lvm)
- SSD-Caching(bcache,zfs(l2arc+zil))
- Festplattenverbünde(RAID5(raidz)/RAID10(striped mirror))
- Performance auf dem Hostsystem und in der virtuellen Maschine
Ich will aus der Geschichte keine Doktorarbeit machen und den Aufwand also in Grenzen halten. D. h. ich werde verzichte darauf, mich Wochen in die einzelnen Themen einzuarbeiten und nehme das, was bei mir an Wissen und Erfahrung bereits da ist und hoffe auf Unterstützung der Experten hier.
Auf was sollte ich bei speziellen Technologien achten, um die grössten Performancebremsen zu vermeiden? Meiner Einschätzung nach lesen hier einige Spezialisten mit was z. B. btrfs und zfs angeht und ich hoffe, dass ich bei Wissenslücken bzw. Konfigurationsfehlern hier Hilfen erhalte.
Bei zfs kenne ich mittlerweile die folgenden wesentlichen wichtigen Kriterien:
- Blockgrösse muss entsprechend der Hardware gesetzt sein(ashift)
- Für das Caching sollte ausreichend RAM zur Verfügung stehen
- Ab einem Füllgrad von >= 80% verringert sich die Performance deutlich
- Nicht gleichmässig gefüllte VDEVs verringern die Performance(Direktes ausbalancieren nur explizit durch export/import möglich).
- nur stabile Features zu verwenden(Wenn RAID5 dann Linux-SW-RAID 5+btrfs-single und nicht btrfs-raid5)
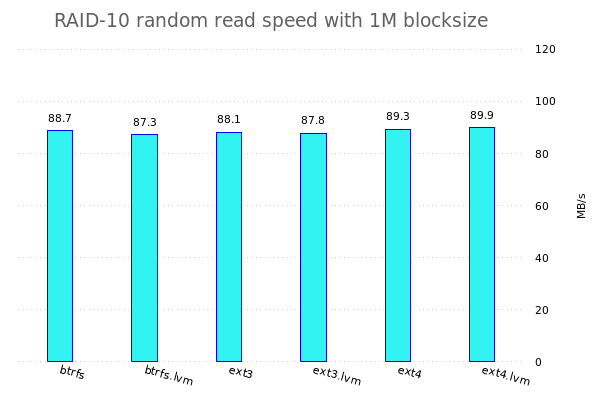
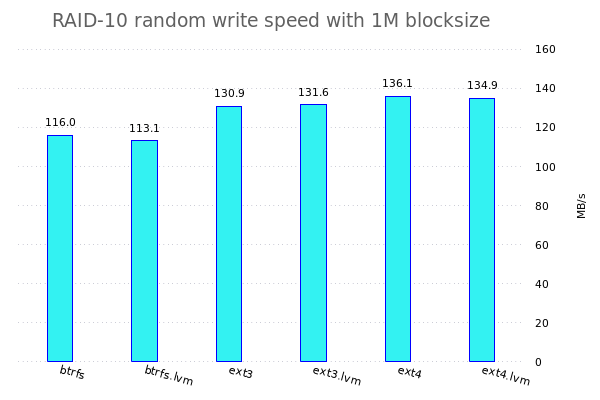
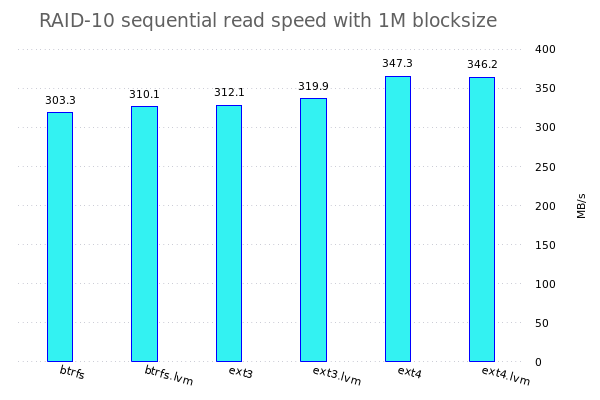
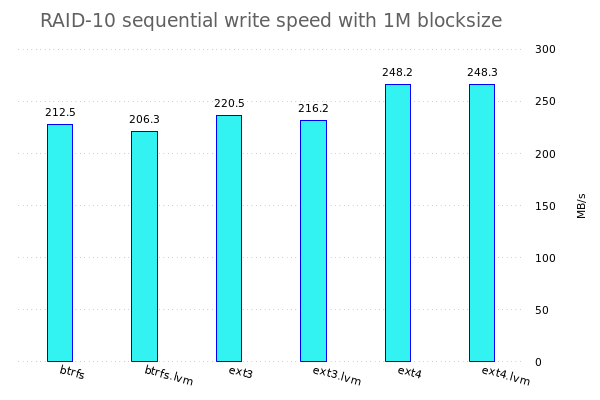
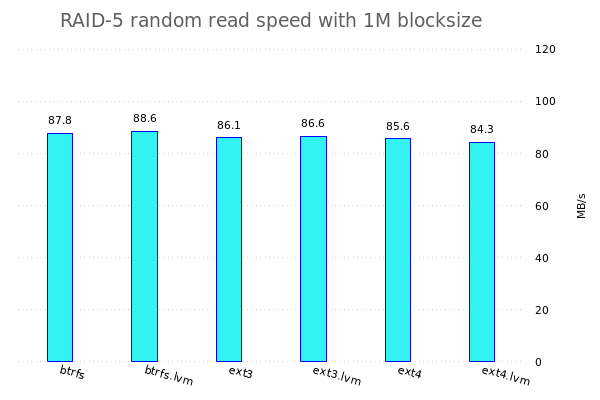
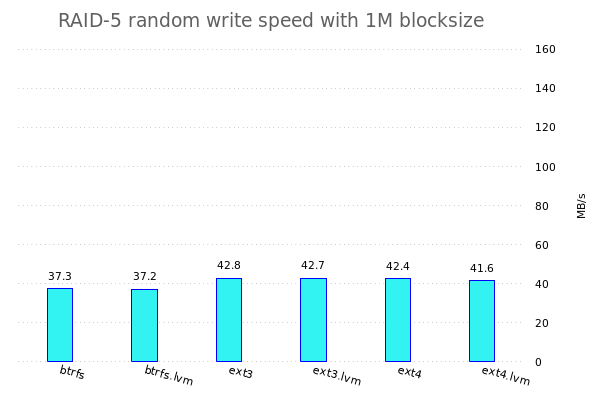
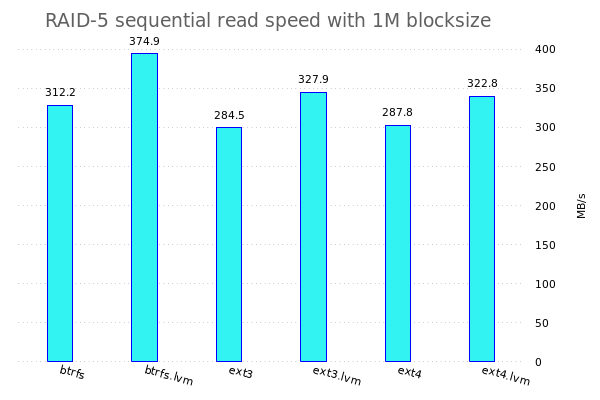
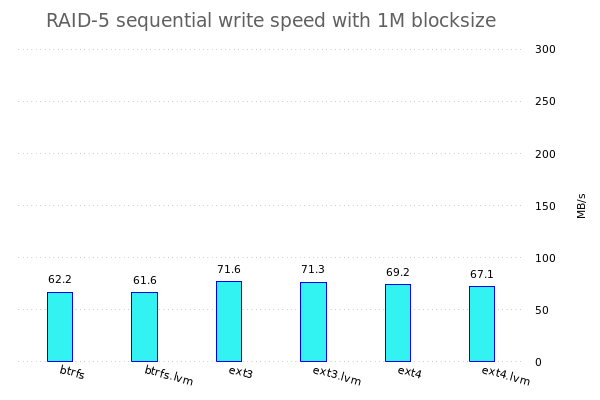
Konkret werde ich fio benutzen um verschiedene Tests auf den verschiedenen Speicherkonfigurationen zu benutzen. Dazu werden jeweils einzelne Dateisysteme, RAID-Arrays, LVM-Konfigurationen, ... erstellt und anschliessend werden da die Tests drauf gefahren.
Aktuelle Hardwareumgebung, die noch erweitert wird ist:
Code: Alles auswählen
# inxi -v2 -C -D -M -R -m
System: Host: pvetest Kernel: 5.3.10-1-pve x86_64 bits: 64 Console: tty 1 Distro: Debian GNU/Linux 10 (buster)
Machine: Type: Desktop Mobo: Intel model: DQ67SW v: AAG12527-309 serial: BQSW133004FE BIOS: Intel
v: SWQ6710H.86A.0067.2014.0313.1347 date: 03/13/2014
Memory: RAM: total: 15.55 GiB used: 825.5 MiB (5.2%)
Array-1: capacity: 32 GiB slots: 4 EC: None
Device-1: Channel A DIMM 0 size: 4 GiB speed: 1333 MT/s
Device-2: Channel A DIMM 1 size: 4 GiB speed: 1333 MT/s
Device-3: Channel B DIMM 0 size: 4 GiB speed: 1333 MT/s
Device-4: Channel B DIMM 1 size: 4 GiB speed: 1333 MT/s
CPU: Topology: Quad Core model: Intel Core i7-2600 bits: 64 type: MT MCP L2 cache: 8192 KiB
Speed: 3675 MHz min/max: 1600/3800 MHz Core speeds (MHz): 1: 3664 2: 3480 3: 3592 4: 3684 5: 2381 6: 2475 7: 3595
8: 3034
Network: Device-1: Intel 82579LM Gigabit Network driver: e1000e
Drives: Local Storage: total: 3.97 TiB used: 13.43 GiB (0.3%)
ID-1: /dev/sda model: N/A size: 930.99 GiB <--- SAS HDD
ID-2: /dev/sdb model: 1 size: 930.99 GiB <--- SAS HDD
ID-3: /dev/sdc model: 2 size: 930.99 GiB <--- SAS HDD
ID-4: /dev/sdd model: 3 size: 930.99 GiB <--- SAS HDD
ID-5: /dev/sde vendor: Intel model: SSDSC2MH120A2 size: 111.79 GiB <--- OS
ID-6: /dev/sdf vendor: Samsung model: SSD 850 EVO M.2 250GB size: 232.89 GiB <--- later: Cachedisk
RAID: Hardware-1: Intel SATA Controller [RAID mode] driver: ahci
Hardware-2: Adaptec AAC-RAID driver: aacraid
# modinfo zfs
filename: /lib/modules/5.3.10-1-pve/zfs/zfs.ko
version: 0.8.2-pve2
license: CDDL
author: OpenZFS on Linux
https://github.com/megabert/storage-benchmarks